Zoo Chatbot deep dive
This deep dive outlines the main concepts of the Zoo Chatbot inner workings.
Natural Language Processing
Natural Language Processing (NLP) is the leverage of computing to understand language. It involves a variety of linguistic datasets, or corpora, along with associated algorithms that transform this data into language models. Zoo Chatbot implements OpenNLP to perform the following NLP tasks, which are explained in following sections:
Tokenization
Zoo Chatbot tokenizes a message into its constituent parts, such as words and punctuation marks, for subsequent part-of-speech tagging. Words are predominantly segmented by white space, with punctuation marks potentially attached in the case of abbreviations. Tokenization decisions are based on a pre-trained maximum entropy model of tokenization data.
Part-of-speech tagging
The tokens are tagged with Penn Treebank part-of-speech labels to indicate word classes and punctuation marks. The choice of tag depends on the context in terms of surrounding tokens. Tagging decisions are based on a pre-trained maximum entropy model of tag data.
Lemmatization
The part-of-speech tags allow tokens to be lemmatized, meaning words are converted into their base form. This allows variants of the same word to be recognised. Lemmatization decisions are based on a pre-trained statistical model of lemmatization data. The training algorithm is based on a PhD dissertation by Grzegorz Chrupala and performs two main functions:
-
Specialised suffixation: many word inflections affect the suffix, for example big can become bigger or biggest. The lemma big is formed by traversing from the end of the inflected word and performing a series of insertions and deletions.
-
Generalised prefixation and suffixation: word forms inapplicable to specialised suffixation are traversed from both the beginning and the end to find the longest common substring, or stem. For example, the Polish words for hard and hardest are trudny and najtrudniejszy respectively, and they share the stem of trudn. The lemma trudny is formed through a series of insertions and deletions.
Chat
The chatbot first implements the other techniques to prepare a message:
The chatbot then trains a maximum entropy model of lemmatized classification data in order to choose the most probable response.
The training data must be converted from text into numerical values for the training algorithm to interpret it. The chatbot implements the bag-of-words model, which involves creating a set of unique words from the data and counting their occurrences. A category with relatively more occurrences of a word is more likely to be selected when that word is present in the input. See the following simplified example based on a small extract of the data:
opening-times what time do you open
opening-times what be your open time
opening-times what be your open hour["bow=be", "bow=do", "bow=hour", "bow=open", "bow=time", "bow=what", "bow=you", "bow=your"][2, 1, 1, 3, 2, 3, 1, 2]Maximum entropy
The maximum entropy algorithm finds a probability distribution that maximises entropy, within constraints dictated by the data. Consider a dice roll as an example. A dice roll has high entropy, meaning that it’s unpredictable, with a uniformly spread out probability distribution (see Figure 1). Empirical training data will indicate this uniform distribution and therefore impose no real constraint, since the model already exhibits maximum entropy.
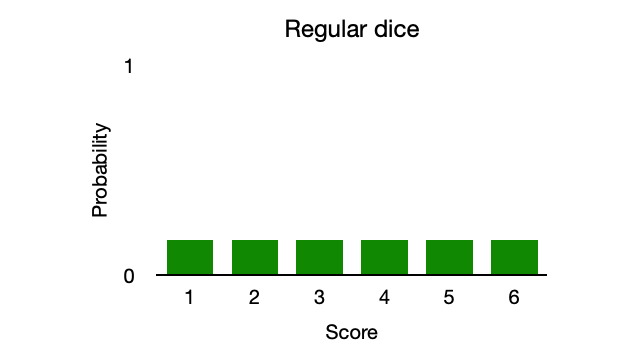
Suppose the dice is weighted in favour of rolling a 6. A naive algorithm might model the dice as always rolling a 6 and therefore indicate zero entropy (see Figure 2). A lack of entropy results in failure to represent outliers; however, as illustrated in Figure 1, too much entropy results in a vague model of randomness. A realistic weighted dice is somewhere between the two probability distributions.
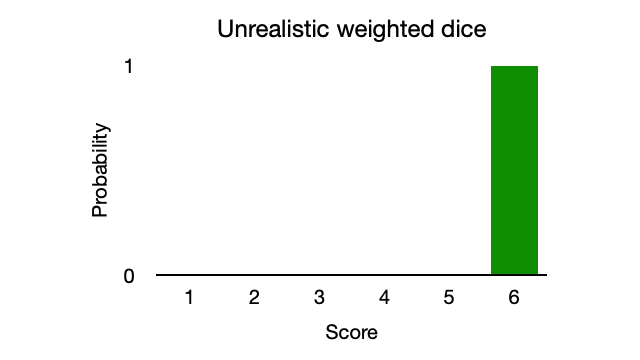
Consider the same weighted dice modelled with maximum entropy. The algorithm will maximise entropy by assigning importance to outliers (values 1-5). However, the outliers will be considered less significant than the more common value of 6 because the algorithm is constrained by the data, which favours a value of 6. The model is specific enough to show trends yet generic enough to include less common outcomes (see Figure 3).
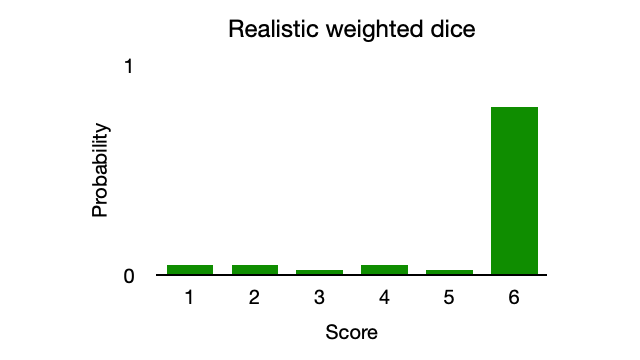
The Zoo Chatbot resembles this weighted dice example, except the algorithm is constrained by the mapping of input data to output data during training, as opposed to a favoured side of a dice. The maximum entropy algorithm favours output based on the mappings whilst maximising the probabilities of less likely outputs.
Learn more
-
See the Zoo Chatbot tutorial for a practical guide of operations.
-
See the API specification for the full specification.